
13
年
專
注
于
數(shù)
字
營
銷






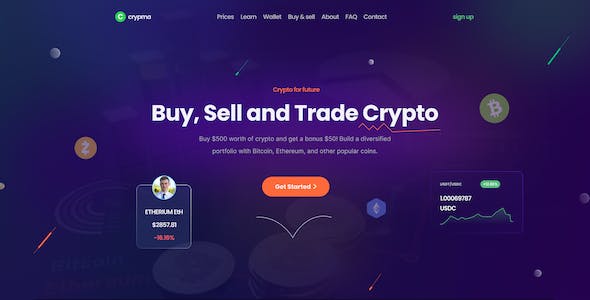
惡意爬蟲是指通過自動化程序來訪問網(wǎng)站,獲取網(wǎng)站數(shù)據(jù),進行非法活動或者侵害網(wǎng)站利益的一類威脅。惡意爬蟲不僅會導致網(wǎng)站流量過大,還可能占用網(wǎng)站資源,對正常用戶產(chǎn)生負面影響。為了保護網(wǎng)站的正常運行和用戶體驗,網(wǎng)站管理員應采取一系列措施來防御惡意爬蟲的攻擊。
在防御惡意爬蟲攻擊時,網(wǎng)站管理員可以采用以下常用方法:
1. 限制訪問頻率:設置網(wǎng)站訪問頻率限制,對指定IP地址的請求進行限制。通過設置訪問頻率限制,可以減少惡意爬蟲對網(wǎng)站的訪問次數(shù),保護網(wǎng)站資源。
2. 驗證碼:在關(guān)鍵操作頁面,如登錄、注冊、評論等地方使用驗證碼。驗證碼是一種基于圖像識別的驗證方式,可以有效防止惡意程序的自動化操作。
3. User-Agent檢測:通過檢測User-Agent字段,判斷請求是否來自真實用戶。惡意爬蟲通常通過偽造User-Agent字段來隱藏自己的身份,所以通過檢測User-Agent可以辨別出惡意爬蟲的請求。
4. Robots.txt文件:通過在網(wǎng)站根目錄下放置Robots.txt文件,指定哪些頁面可以被爬蟲訪問,哪些頁面禁止被訪問。網(wǎng)站管理員可以通過編輯Robots.txt文件,限制惡意爬蟲的訪問范圍。
5. IP封禁:通過監(jiān)控網(wǎng)站的訪問日志,及時發(fā)現(xiàn)可疑IP地址,并將其列入黑名單,限制其訪問網(wǎng)站。封禁可疑IP地址是一種常見的防御惡意爬蟲攻擊的手段。
6. 人機驗證:通過人機驗證技術(shù),如滑塊驗證碼、點擊驗證碼等,判斷請求是否來自真實用戶。人機驗證可以有效區(qū)分人類用戶和惡意爬蟲,提升網(wǎng)站的安全性。
7. 反爬蟲策略:在網(wǎng)站代碼中添加一些反爬蟲策略,如隱藏關(guān)鍵數(shù)據(jù)、使用動態(tài)生成頁面等。這些策略可以增加惡意爬蟲破解的難度,減少被爬蟲訪問的可能性。
除了以上常用方法,網(wǎng)站管理員還可以根據(jù)實際情況選擇其他防御手段,如使用CDN服務、使用Web應用防火墻等。在防御惡意爬蟲的過程中,需要持續(xù)監(jiān)控網(wǎng)站訪問日志,并及時更新防御策略,以應對不斷變化的惡意爬蟲攻擊。




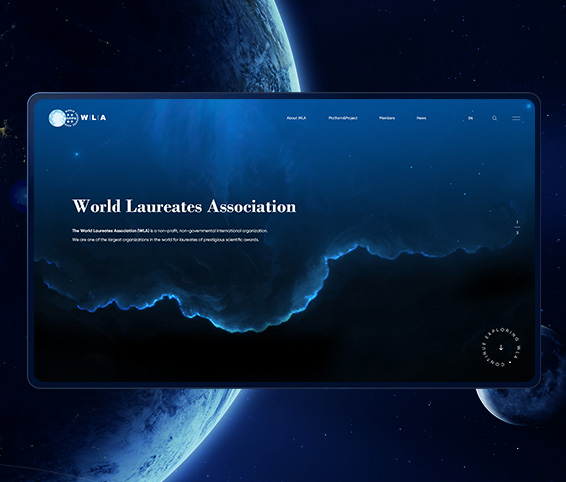
 生物醫(yī)藥網(wǎng)站建設
生物醫(yī)藥網(wǎng)站建設 IT科技網(wǎng)站建設
IT科技網(wǎng)站建設 網(wǎng)站集群網(wǎng)站建設
網(wǎng)站集群網(wǎng)站建設 教育培訓網(wǎng)站建設
教育培訓網(wǎng)站建設 智慧黨建網(wǎng)站建設
智慧黨建網(wǎng)站建設 上市公司網(wǎng)站建設
上市公司網(wǎng)站建設 小程序
小程序 APP開發(fā)
APP開發(fā) 系統(tǒng)開發(fā)
系統(tǒng)開發(fā) 確定建站目標
確定建站目標 深度調(diào)研策劃
深度調(diào)研策劃 建立視覺體系
建立視覺體系 創(chuàng)意視覺設計
創(chuàng)意視覺設計 前端交互開發(fā)
前端交互開發(fā) 短視頻推廣
短視頻推廣 短視頻競價
短視頻競價 短視頻矩陣
短視頻矩陣 抖音視頻營銷
抖音視頻營銷 媒體軟文營銷
媒體軟文營銷 網(wǎng)站SEO優(yōu)化
網(wǎng)站SEO優(yōu)化 系統(tǒng)私有定制
系統(tǒng)私有定制 數(shù)字運維監(jiān)測
數(shù)字運維監(jiān)測 集錦站群系統(tǒng)
集錦站群系統(tǒng) 集錦ERP系統(tǒng)
集錦ERP系統(tǒng) 集錦知識付費
集錦知識付費 數(shù)字內(nèi)容系統(tǒng)
數(shù)字內(nèi)容系統(tǒng) 集錦電商系統(tǒng)
集錦電商系統(tǒng)
 立即咨詢
立即咨詢





 立即咨詢
立即咨詢



 撥打電話獲取報價
撥打電話獲取報價







